{kind=link}
Bir web sitesinin Google gibi arama motorları tarafından ne kadar sık taranacağını belirleyen sınırlı bir kapasite vardır. Bu kapasiteye tarama bütçesi (crawl budget) denir. Basit bir ifadeyle, Googlebot’un sitenize ayırdığı günlük “ziyaret kontenjanı”dır.
Tarama bütçesini bir restoran menüsü gibi düşünebilirsiniz. Googlebot, restoranınıza gelen bir müşteri gibidir. Ancak müşterinin hem zamanı hem de iştahı sınırlıdır, yani menüdeki her şeyi yiyemez. Eğer menünüz gereksiz yiyeceklerle (birbirinin aynısı tabaklar, lezzetsiz yemekler ya da tekrar eden seçenekler) dolu olursa müşteri asıl özel yemeklerinizi (en iyi pişirdiğiniz imza yemekler veya en çok tercih edilen tabaklar) deneyemez. Ancak menünüzü sadeleştirip en lezzetli ve değerli yemeklerinizi öne çıkarırsanız müşteri (Googlebot) de doğru seçimleri yapar ve restoranınız (web siteniz) daha iyi bir şöhrete kavuşur.
Tarama Bütçesi Nedir?
Tarama bütçesi (crawl budget), arama motoru botlarının belirli bir zaman diliminde bir web sitesinde tarayabileceği sayfa sayısını ifade eder. Bu sayı hem Google’ın teknik kısıtları hem de sitenizin yanıt verme kapasitesi dikkate alınarak belirlenir. Googlebot, sitenizi tararken sunucuyu aşırı yüklememek için belli bir limit koyar ve bu limit sizin tarama bütçenizdir.
Google bu kavramı iki temel unsurla açıklar:
- Tarama Oranı Limiti (Crawl Rate Limit): Sunucunun kaldırabileceği yük. Eğer siteniz yavaş yanıt veriyorsa Googlebot daha az istek gönderir. Sunucunuz hızlı ve sağlıklı çalışıyorsa tarama oranı artabilir.
- Tarama Talebi (Crawl Demand): Google’ın içeriklerinizi ne kadar önemli ve güncel gördüğüyle ilgilidir. Popüler, sık güncellenen veya trend konulara ait sayfalar daha sık taranır.
Örneğin, bir haber sitesi düşünelim. Günde yüzlerce yeni içerik üretiyor. Google, bu sitenin sürekli güncellendiğini bildiği için tarama talebini yüksek tutar. Buna karşılık, yıllardır aynı içeriğe sahip küçük bir kurumsal siteye çok sık uğramaz.
Tarama Bütçesi SEO için Neden Önemlidir?
Tarama bütçesi, doğrudan bir sıralama faktörü olmasa da indeksleme sürecinin merkezinde yer alır. Çünkü bir sayfanın Google arama sonuçlarında yer alabilmesi için önce taranması, ardından dizine eklenmesi gerekir. Eğer Googlebot sitenizdeki önemli sayfaları tarayamıyor ya da çok geç tarıyorsa bu sayfaların sıralama potansiyeli de gecikir veya hiç gerçekleşmez.
- Hızlı İndeksleme: Yeni yayınlanan içeriklerin, özellikle haber siteleri veya kampanya sayfaları gibi zaman hassasiyeti olan sayfaların hızlı indekslenmesi için tarama bütçesinin doğru kullanılması şarttır.
- Önemli Sayfaların Önceliği: Eğer bütçe gereksiz sayfalara (parametreli URL’ler, yinelenen içerikler, filtreleme sayfaları) harcanıyorsa kategori, ürün veya hizmet sayfalarınız geri planda kalabilir.
- Site Sağlığının Göstergesi: Çok fazla 404 hatası, redirect chain veya kırık link tarama bütçesini boşa harcar. Bu da Google’a sitenizin iyi yönetilmediğini gösterir.
Örneğin, bir e-ticaret sitesinde binlerce ürün vardır. Eğer Googlebot her gün yüzlerce “stokta olmayan ürün” sayfasını taramakla meşgulse yeni eklenen ürünleri çok daha geç keşfeder. Bu da satış kaybına yol açabilir.
Hangi Siteler Tarama Bütçesiyle İlgilenmeli?
Google, küçük ölçekli web sitelerinin büyük çoğunluğu için tarama bütçesinin kritik bir sorun olmadığını açıkça belirtir. Çünkü yüzlerce veya birkaç bin sayfadan oluşan standart siteler, Googlebot tarafından genellikle aynı gün içinde rahatlıkla taranır. Ancak bazı durumlarda tarama bütçesi doğrudan gündeme gelir:
Tarama bütçesini önemsemesi gereken siteler:
- Büyük ölçekli siteler: 100.000’den milyonlarca sayfaya sahip e-ticaret, haber veya forum siteleri.
- Sürekli güncellenen siteler: Günlük içerik eklenen haber portalları, sık sık ürün stoğu değişen e-ticaret siteleri.
- Parametreli URL üreten siteler: Filtreleme, sıralama veya arama parametreleriyle çok sayıda varyasyon sayfası üreten platformlar.
- Uluslararası siteler: Birden fazla dil ve ülke versiyonuna sahip siteler. (Hreflang yapılandırması nedeniyle aynı sayfanın farklı versiyonları taranabilir.)
- Yapısal sorun yaşayan siteler: Çok sayıda kırık link, redirect chain veya duplicate içerik barındıran siteler.
Tarama bütçesiyle daha az ilgilenmesi gereken siteler
- 1.000 sayfadan az içeriğe sahip kişisel bloglar.
- Kurumsal tanıtım siteleri.
- İçerik güncellemeleri seyrek yapılan küçük işletme siteleri.
Örneğin, 200 sayfalık bir mimarlık ofisi web sitesi düşünelim. Bu sitede tarama bütçesi sorun olmaz. Çünkü Google, tüm sayfaları aynı gün içinde tarayabilir. Ama 1 milyon ürünlü bir e-ticaret sitesi için aynı şey geçerli değildir. Eğer tarama bütçesi boşa harcanıyorsa yeni ürünler günlerce dizine eklenmeyebilir.
Tarama Bütçesini Etkileyen Faktörler
Tarama bütçesi, sabit bir sayı değildir; sitenizin teknik altyapısı, içerik yapısı ve Google’ın sitenize duyduğu ilgiye göre değişir. Sunucu hızından URL yapısına, yönlendirmelerden kopya içeriklere kadar birçok unsur, Googlebot’un sitenizde ne kadar verimli çalışacağını belirler.
Site Hızı ve Sunucu Yanıt Süresi
Tarama bütçesini doğrudan etkileyen en önemli faktörlerden biri site hızı ve sunucunun yanıt verme süresidir. Googlebot, sitenizi tararken sunucunuza gönderdiği her isteğin ne kadar hızlı yanıtlandığını ölçer. Bu ölçüm sonucuna göre, aynı zaman diliminde kaç sayfa tarayabileceğini belirler.
- Hızlı sunucular: Yanıt süresi düşük olduğu için Googlebot daha fazla sayfa tarayabilir.
- Yavaş sunucular: Yanıt süresi yüksekse Googlebot daha az istek gönderir. Çünkü sitenizi yavaşlatıp kullanıcı deneyimini bozmak istemez.
Örneğin, bir e-ticaret sitenizin olduğunu düşünün. Sunucunuzun yanıt süresi ortalama 1 saniyeyse Googlebot 10 dakika içinde yüzlerce ürün sayfasını tarayabilir. Ancak aynı sunucu 5 saniyede yanıt veriyorsa bu süre içinde sadece onlarca sayfa taranabilir. Sonuç olarak yeni ürünlerinizin Google’a geç yansıması, satış kaybı anlamına gelir. Kısacası siteniz ne kadar hızlı yüklenirse Googlebot aynı süre içinde o kadar fazla sayfa tarar. Bu da tarama bütçenizin verimli kullanılmasını sağlar.
İç Link Yapısı ve Site Mimarisi
Googlebot’un sitenizi nasıl keşfettiğini belirleyen en kritik unsurlardan biri iç link yapısıdır. Bir sitenin mimarisi ne kadar düzenli ve erişilebilir olursa Google’ın önemli sayfaları bulup taraması da o kadar kolay olur.
- Düz (Flat) Mimari: Düz mimari, sitenizdeki sayfaların ana sayfadan ya da yalnızca birkaç tıkla erişilebildiği yapıyı ifade eder. Bu modelde site yapısı sade ve erişim kolaydır. Böylece Googlebot, sitenizdeki tüm önemli sayfalara kısa sürede ulaşabilir ve tarama bütçesi gereksiz yere harcanmaz. Örneğin, bir e-ticaret sitesinde ürün sayfalarının en fazla 3 tıkla ana sayfadan ulaşılabilir olması, düz mimariye iyi bir örnektir.
- Derin (Deep) Mimari: Derin mimari ise önemli sayfalara erişmek için çok fazla tıklama gerektiren yapılardır. Bu tür sitelerde kullanıcı deneyimi zorlaşırken, Googlebot’un da sayfalara ulaşması problemli hale gelir. Sonuç olarak tarama bütçesi etkin bir şekilde kullanılamaz ve kritik sayfaların indekslenmesi gecikebilir.
- Orphan (Yetim) Sayfalar: Orphan sayfalar, site içinde hiçbir yerden link almayan, yalnızca doğrudan URL yazılarak ulaşılabilen sayfalardır. Googlebot bu tür sayfaları çoğunlukla yalnızca sitemap üzerinden keşfedebilir. Bu da taranma sürecini geciktirir veya bazı sayfaların hiç taranmamasına yol açar. Orphan sayfaların önüne geçmek için düzenli site analizleri yapılmalı, bu sayfalar belirlenmeli ve uygun iç linklerle site yapısına entegre edilmelidir.
Sonuç olarak Googlebot, sitenizde adeta bir gezgin gibi hareket eder. Her link, onun için yeni bir yol demektir. Eğer yollar karmaşık, çok katmanlı veya kopuksa bot enerjisini yanlış yerlerde harcar. Bu da kritik sayfalarınızın taranma ve dizine eklenme süresini olumsuz etkiler.
Yönlendirmeler (Redirect Chains ve Loops)
Tarama bütçesini tüketen en yaygın sorunlardan biri de gereksiz veya hatalı yönlendirmelerdir. Googlebot her yönlendirmeyi ayrı bir tarama adımı olarak görür. Bu da hem zaman kaybı hem de sunucuya fazladan yük anlamına gelir.
- Redirect Chains (Yönlendirme Zincirleri): Bir URL’nin başka bir URL’ye, onun da başka bir URL’ye yönlendirilmesiyle (A → B → C) oluşur. Bu durum her adımda hem kullanıcıya hem de Googlebot’a zaman kaybettirir. Zincir çok uzadığında Google hedef sayfaya ulaşmaktan vazgeçebilir. Bu nedenle zincirler yerine doğrudan tek adımlı yönlendirmeler (A → C) tercih edilmelidir.
- Redirect Loops (Yönlendirme Döngüleri): Bir URL’nin başka bir URL’ye yönlendirilip tekrar ilk URL’ye dönmesiyle (A → B → A) ortaya çıkar. Bu durumda Googlebot sonsuz bir döngüye girer, sayfayı tarayamaz ve tarama bütçesi tamamen boşa gider. Aynı zamanda kullanıcı deneyimi açısından da ciddi sorunlara yol açar çünkü ziyaretçi hiçbir zaman hedef içeriğe ulaşamaz.
Sonuç olarak her yönlendirme, tarama bütçesinden ekstra kaynak tüketir. Gereksiz zincirler veya döngüler, Google’ın önemli sayfalarınıza ulaşmasını engelleyebilir.
Kopya İçerik (Duplicate Content)
Tarama bütçesinin boşa harcanmasına yol açan en yaygın problemlerden biri de kopya içerik (duplicate content) sorunudur. Kopya içerik, aynı veya çok benzer içeriklerin farklı URL’lerde yer alması durumudur.
- URL parametreleri: Filtreleme, sıralama veya kampanya etiketleri (?utm_source=, ?sort=asc).
- HTTP/HTTPS – www/non-www farkları: Aynı sayfa birden fazla versiyonda erişilebilir olabilir.
- Mobil ve masaüstü sürümleri: Ayrı ayrı URL’lerde tutuluyorsa içerik tekrarına yol açar.
- Kopyalanmış ürün açıklamaları: E-ticaret sitelerinde farklı ürünler için aynı açıklamanın kullanılması.
- Yazılım kaynaklı çoğaltmalar: CMS hataları veya yanlış yapılandırılmış kategori/etiket sayfaları.
Googlebot aynı veya benzer içerikleri tekrar tekrar taradığında, bu durum tarama bütçesini tüketir. Bunun sonucu olarak:
- Önemli sayfalar daha geç taranır.
- Google hangi sayfanın asıl (canonical) olduğunu belirlemekte zorlanabilir.
- SEO performansınız olumsuz etkilenir.
Örneğin, bir e-ticaret sitesinde aynı ayakkabı modeli hem “erkek ayakkabı” hem de “indirimli ürünler” kategorilerinde farklı URL’lerde bulunuyor. İçerikler neredeyse aynı olduğundan Google iki URL’yi de tarar, ama birini seçmek zorunda kalır. Bu da gereksiz tarama tüketimidir.
Dinamik URL’ler ve Parametreler
Tarama bütçesini boşa harcayan en büyük sorunlardan biri de dinamik URL’ler ve parametrelerdir. Özellikle e-ticaret siteleri ve forumlarda, filtreleme, sıralama ve arama parametreleri yüzünden aynı içerik farklı URL’lerde çoğaltılır.
- example.com/urun?renk=kirmizi
- example.com/urun?renk=kirmizi&beden=42
- example.com/urun?renk=kirmizi&beden=42&sort=fiyat-artan
Yukarıdaki dinamik URL’lerin her biri teknik olarak farklı bir URL’dir, fakat içerik çoğu zaman aynıdır. Googlebot bu sayfaları taramaya başladığında tarama bütçesi hızla tükenir. Peki, bunlar neden bir sorun teşkil eder?
- Aynı ürün sayfasının yüzlerce varyasyonu taranabilir.
- Google önemli sayfalarınıza geç ulaşır.
- Dizine çok sayıda gereksiz URL eklenerek “index bloat” sorunu ortaya çıkar.
Örneğin, bir online mağazada kullanıcılar “renk, beden, fiyat” gibi filtreler kullandığında, tek bir ürün için yüzlerce farklı URL oluşabilir. Bu durumda Googlebot her varyasyonu taramaya çalışır ve asıl ürün sayfanız için ayrılması gereken bütçe boşa gider.
Sitemap ve Robots.txt Dosyaları
Tarama bütçesinin verimli kullanılmasında en kritik araçlardan ikisi sitemap.xml ve robots.txt dosyalarıdır. Bu iki dosya, Googlebot’a “hangi sayfaların önemli olduğunu, hangilerinin taranmasına gerek olmadığını” anlatır.
Sitemap (Site Haritası)
Sitemap, Google’a dizine eklenmesi gereken URL’lerin net bir listesini sunar. Bu nedenle yalnızca canonical ve değerli sayfaların site haritasında yer alması gerekir. 404 hatası veren, yönlendirilmiş, noindex etiketine sahip veya yinelenen içerikler site haritasına kesinlikle dahil edilmemelidir. Ayrıca site haritasının düzenli olarak güncellenmesi önemlidir; eklenen yeni içerikler anında burada görünmelidir. Büyük ölçekli sitelerde ise tek bir dev sitemap yerine kategori bazlı ya da bölümlere ayrılmış birden fazla sitemap kullanmak, Googlebot’un tarama sürecini kolaylaştırır.
Robots.txt
Robots.txt dosyası, Googlebot’a sitenizde hangi sayfaları taramaması gerektiğini bildirir. Özellikle filtreleme, sıralama veya site içi arama sonuç sayfaları gibi değer katmayan bölümler bu dosya üzerinden engellenebilir. Ayrıca gereksiz parametreli URL’lerin engellenmesi de tarama bütçesinin verimli kullanılmasına yardımcı olur. Ancak burada dikkat edilmesi gereken en önemli nokta, önemli sayfaların yanlışlıkla engellenmemesidir. Örneğin, /blog ya da /urun klasörlerinin robots.txt ile engellenmesi, sitenizin kritik içeriklerinin Google tarafından hiç taranmamasına yol açabilir. Bir e-ticaret sitesinde “/arama?q=ayakkabi” gibi sınırsız varyasyona sahip arama sonuç sayfalarının engellenmesi ise Googlebot’un zamanını boşa harcamasını önler ve tarama bütçesinin ürün sayfalarına odaklanmasını sağlar.
Hreflang ve Uluslararası SEO Etkisi
Birden fazla dil ve ülke için içerik üreten sitelerde hreflang etiketleri doğru kullanılmazsa, tarama bütçesi ciddi şekilde boşa harcanabilir.
Hreflang etiketi, Google’a aynı içeriğin farklı dil veya bölgeye özel versiyonlarını gösteren bir HTML işaretidir. Örneğin:
<link rel="alternate" hreflang="en" href="https://ornek.com/en/" />
<link rel="alternate" hreflang="tr" href="https://ornek.com/tr/" />Bu etiket sayesinde Google, hangi sayfanın hangi kullanıcıya gösterileceğini anlar. Peki, sorun nerede çıkar?
- Yanlış yapılandırma: Aynı sayfa için yüzlerce dil/ülke kombinasyonu yanlış işaretlenirse Google gereksiz şekilde tüm varyasyonları tarar.
- Kopya içerik algısı: Farklı URL’lerde aynı içerik sunuluyorsa Google bunları ayrı ayrı tarayarak bütçeyi tüketir.
- Eksik hreflang eşlemesi: Bir dil sürümünde hreflang etiketi eklenmiş ama diğerinde yoksa Google ilişkileri yanlış kurabilir ve fazladan tarama yapabilir.
Örneğin, bir otel rezervasyon sitesi düşünün. Aynı sayfanın İngilizce, Almanca, Fransızca ve Türkçe versiyonları var. Eğer hreflang etiketleri doğru işlenmemişse Google hepsini ayrı ayrı ve bağımsız sayfalar gibi tarar. Bu durum hem tarama bütçesini boşa tüketir hem de dizin karmaşasına yol açar.
404, Soft 404 ve Sunucu Hataları
Tarama bütçesinin boşa gitmesine neden olan bir diğer kritik unsur da hata kodlarıdır. Googlebot her hata aldığında zaman ve kaynak harcar; bu da önemli sayfaların taranmasını geciktirir.
- 404 Hataları (Not Found): 404 hataları, sunucuda artık var olmayan bir sayfaya istek gönderildiğinde ortaya çıkar. Aslında gerçekten silinen sayfalar için 404 yanıtı normaldir. Fakat aktif linkler hâlâ bu sayfalara yönlendiriyorsa sorun haline gelir. Çok sayıda 404 hatası, Google’ın gereksiz URL’lere zaman harcamasına yol açar ve tarama bütçesinin boşa gitmesine neden olabilir. Bu yüzden sitenizdeki kırık linkleri düzenli olarak tespit edilmeli ve ya doğru sayfalara yönlendirilmelidir.
- Soft 404 Hataları: Soft 404, kullanıcıya “sayfa bulunamadı” benzeri bir içerik gösterilmesine rağmen sunucunun 200 (başarılı) yanıt döndürmesi durumudur. Bu durumda Googlebot, ilgili sayfayı normal bir içerik gibi algılar, gereksiz yere tarar ve dizine eklemeye çalışır. Sonuç olarak hem tarama bütçesi boşa harcanır hem de dizin kalitesi düşer. Bu tip sayfaların mutlaka doğru HTTP durum koduyla, yani 404 veya 410 ile yanıt vermesi gerekir.
- 5xx Sunucu Hataları: 5xx hataları (500, 502, 503 vb.), sunucunun isteği işleyememesi durumunda ortaya çıkar. Eğer Google bu tür hataları sık görürse sitenizin kapasitesinin düşük olduğunu düşünebilir ve tarama hızını otomatik olarak azaltır. Bu nedenle sunucu kaynaklarının optimize edilmesi büyük önem taşır. Ayrıca bakım dönemlerinde 503 yanıt kodu ile birlikte “Retry-After” başlığı kullanmak, Google’a sitenin geçici olarak erişilemediğini bildirmenin en doğru yoludur.
Örneğin, bir e-ticaret sitesinde stoktan düşen ürünler için 404 yerine 200 yanıt döndürülüp “Ürün bulunamadı” mesajı gösterildiğini düşünelim. Googlebot bu sayfaları normal içerik gibi tarar, ancak kullanıcıya değer sunmaz. Bu durum tarama bütçesinin boşa harcanmasına sebep olur.
Renderlama Türü (Server-side ve Client-side Rendering)
Googlebot’un bir sayfayı tarayıp anlaması, sayfanın nasıl işlendiğine (renderlandığına) bağlıdır. Bu noktada iki temel yöntem vardır:
- Server-side Rendering (SSR): Server-side Rendering’de (SSR) sayfanın HTML içeriği doğrudan sunucuda hazırlanır ve tarayıcıya, dolayısıyla Googlebot’a eksiksiz şekilde gönderilir. Bu yöntem sayesinde Google sayfayı kolayca tarar ve indeksler; ek bir işlem yapmasına gerek kalmaz. Ancak bu yaklaşımın dezavantajı, sunucunun daha fazla işlem gücü harcamasını gerektirmesidir. Özellikle yüksek trafikli sitelerde bu durum performans üzerinde ek yük oluşturabilir.
- Client-side Rendering (CSR): Client-side Rendering’de (CSR) sayfanın başlangıçtaki HTML’i genellikle boştur veya çok sınırlı içerik barındırır. Asıl içerik, JavaScript çalıştırıldıktan sonra tarayıcıda yüklenir. Googlebot JavaScript’i işleyebildiği için sayfayı indekslemesi mümkündür; fakat bu süreç ek zaman ve kaynak tüketir. Dolayısıyla CSR, tarama bütçesi açısından SSR’ye göre dezavantaj yaratır ve kritik içeriklerin geç keşfedilmesine yol açabilir.
Bir e-ticaret sitesi düşünelim. Ürün sayfasındaki başlık, açıklama ve fiyat bilgisi SSR ile direkt sunucudan gelir. Ancak kullanıcı yorumları JavaScript ile sonradan yüklenir. Bu durumda Googlebot ürün bilgilerini kolayca tarar, yorumlar için ekstra kaynak kullanır.
Tarama Bütçesi Nasıl Optimize Edilir?
Tarama bütçesini optimize etmek, Googlebot’un zamanını en değerli sayfalarınıza ayırmasını sağlamak demektir. Bunun için hem teknik düzenlemeler hem de içerik stratejileri devreye girer. Gereksiz veya düşük kaliteli sayfaların önünü kapatmak, önemli içeriklere kolay erişim sunmak ve sitenizin performansını artırmak, bütçenizin verimli kullanılmasının temel yoludur.
1. Gereksiz URL’lerin Engellenmesi
Tarama bütçesinin en büyük israf alanlarından biri gereksiz URL’lerdir. Googlebot her URL’yi ayrı bir kaynak olarak görür ve bunları taramaya çalışırken zaman kaybeder. Özellikle büyük sitelerde robots.txt kullanımı, parametre yönetimi ve arama/filtreleme sayfalarının kontrol altına alınması kritik öneme sahiptir.
Robots.txt ile Gereksiz URL’leri Engelleme
Robots.txt dosyası, Googlebot’a hangi bölgelere girmemesi gerektiğini bildirir. Engellenmesi gereken sayfalar:
- /arama/ veya dahili arama sonuçları
- /cart/, /checkout/ gibi kullanıcıya özel alanlar
- ?sort=, ?filter= gibi sınırsız varyasyon üreten parametreler
Örnek dosya:
User-agent: *
Disallow: /arama/
Disallow: /cart/
Disallow: /checkout/
Disallow: /*?sort=
Disallow: /*?filter=Not: Robots.txt yalnızca taramayı engeller, dizine eklenmeyi değil. Bu nedenle kritik olmayan sayfalar için “noindex” etiketi de kullanılabilir.
Parametreli URL’lerin Kontrolü
E-ticaret sitelerinde renk, beden, fiyat sıralaması gibi filtreler yüzünden yüzlerce varyasyon oluşabilir.
- Canonical etiketleri ile asıl sayfayı işaretleyin.
- Gereksiz parametreleri robots.txt veya Search Console parametre ayarları ile engelleyin.
- Gerekirse “noindex” etiketi uygulayın.
Örnek: /urun?renk=kirmizi&beden=42 ile /urun?renk=kirmizi&beden=42&sort=fiyat-artan aslında aynı ürün sayfasıdır. Google bu ikisini taradığında, değerli tarama bütçeniz boşa gider.
Filtreleme ve Arama Sayfaları
Site içi arama veya filtreleme sayfaları neredeyse sınırsız sayıda URL üretebilir.
Örnek: /arama?q=ayakkabi&renk=kirmizi&beden=42
Google bu tür URL’leri taradığında, asıl ürün sayfalarına ayıracağı zamanı kaybeder.
- Arama sayfalarını robots.txt ile engelleyin.
- Filtreleme sayfalarında noindex etiketi kullanın.
- Önemli kategori ve ürün sayfalarına odaklanın.
Gereksiz URL’lerin kontrol altına alınması, tarama bütçesi optimizasyonunun en temel adımıdır. Robots.txt, canonical etiketleri ve noindex kullanımı sayesinde Googlebot’un enerjisi, gerçekten değerli sayfalara yönlendirilir.
2. Sitemap Optimizasyonu
Sitemap, Googlebot için bir yol haritasıdır. Doğru yapılandırılmış bir sitemap, tarama bütçesinin boşa harcanmasını engeller ve önemli sayfaların hızlı keşfedilmesini sağlar. Ancak hatalı veya gereksiz URL’lerle dolu bir sitemap, tam tersine bütçeyi israf eder.
Sadece Canonical URL’ler
- Site haritasına yalnızca canonical olarak belirlenmiş URL’ler eklenmelidir.
- Yinelenen sayfalar, yönlendirme yapan URL’ler, noindex etiketli veya parametreli adresler sitemap’te yer almamalıdır.
- Böylece Googlebot, gerçekten dizine alınması gereken sayfalara odaklanır.
Örnek: Bir ürün hem “/indirim/urun-123” hem de “/urun-123” adresinden erişilebiliyorsa site haritasında yalnızca kanonik olan “/urun-123” bulunmalıdır.
Güncel ve Temiz Site Haritası
- Yeni içerikler eklendiğinde site haritası otomatik güncellenmelidir.
- Silinen sayfalar, 404 veya yönlendirme durumuna düşen URL’ler site haritasından kaldırılmalıdır.
- Büyük sitelerde, kategori bazlı veya bölümlere ayrılmış birden fazla site haritası kullanılabili. Örneğin; “haberler-sitemap.xml”, “urunler-sitemap.xml”.
- Site haritasının durumu düzenli olarak Search Console üzerinden kontrol edilmelidir.
Site haritanızın, Google’a sunduğunuz bir davetiyedir. Sadece doğru ve değerli sayfaları içerirse tarama bütçesi tam verimle kullanılır.
3. İç Bağlantı Optimizasyonu
Googlebot’un sitenizi keşfetme biçimi, tıpkı bir ziyaretçinin menüler ve linkler üzerinden gezinmesine benzer. İç link yapısı, tarama bütçesinin yönünü belirleyen en kritik unsurlardan biridir.
Kırık Linkleri Kaldırma
Kırık linkler, yani 404 hatası veren URL’lere yönlendiren bağlantılar, Googlebot’un boşa zaman harcamasına neden olur. Bu durumda tarama bütçesi hatalı sayfalarda tüketilir ve önemli içeriklerin taranması gecikebilir.
- Düzenli site analizleri yaparak kırık linkleri tespit edin.
- Silinen sayfaları yönlendirin.
- Site içinde hâlâ var olmayan sayfalara verilen linkleri kaldırın.
Önemli Sayfalara Link Verme
İç linkler, Googlebot’un sitenizde hangi sayfaların öncelikli olduğunu anlamasına yardımcı olur. Bu nedenle ana sayfadan en kritik kategori ve ürün sayfalarına doğrudan link verilmesi önemlidir.
- Ana sayfadan en kritik kategori ve ürün sayfalarına link verin.
- Blog yazılarında alakalı içeriklere iç link ekleyin.
- Orphan sayfaları iç bağlantılarla site ağına dahil edin.
Sonuç olarak iç link optimizasyonu hem kullanıcılar hem de Googlebot için bir yol haritası işlevi görür. Kırık linkleri temizleyip stratejik iç linkler oluşturmak, tarama bütçesinin en verimli şekilde kullanılmasını sağlar.
4. Sayfa Hızı İyileştirmeleri
Site hızı, yalnızca kullanıcı deneyimini değil, aynı zamanda tarama bütçesini de doğrudan etkileyen bir faktördür. Googlebot’un bir sayfayı ne kadar hızlı yükleyebildiği, aynı süre içinde kaç sayfa tarayabileceğini belirler. Yavaş siteler, tarama bütçesinin hızla tükenmesine yol açar.
Google, sayfa hızını ölçmek için Core Web Vitals metriklerini kullanır. Bu metrikler hem SEO sıralamalarında hem de tarama verimliliğinde rol oynar:
- LCP (Largest Contentful Paint): Sayfanın ana içeriğinin ne kadar hızlı yüklendiğini ölçer.
- FID (First Input Delay): Kullanıcının ilk etkileşime ne kadar sürede yanıt verildiğini gösterir.
- CLS (Cumulative Layout Shift): Sayfa yüklenirken oluşan görsel kaymaları ölçer.
Bu metriklerde zayıf performans sergileyen siteler hem kullanıcılar hem de Googlebot için “yavaş” algısı yaratır.
- CDN (Content Delivery Network): İçeriği kullanıcıya en yakın sunucudan yükleyin.
- Görsel optimizasyonu: Görselleri WebP veya AVIF formatına dönüştürün, boyutlarını küçültün.
- CSS ve JavaScript küçültme: Gereksiz kodları temizleyin, dosyaları minify edin.
- Lazy load kullanımı: Görselleri yalnızca ekranda göründüklerinde yükleyin.
- Sunucu iyileştirmeleri: Daha güçlü hosting veya bulut altyapısına geçin.
Örneğin, bir haber sitesi düşünelim. Eğer ana sayfadaki görseller optimize edilmemişse Googlebot sayfayı yüklemek için fazladan saniyeler harcar. Bu da aynı tarama süresinde daha az haberin taranması anlamına gelir.
5. Gereksiz Kaynakların Engellenmesi (JS, CSS, Rest API vb.)
Googlebot bir sayfayı tararken sadece HTML’i değil, o sayfanın yüklediği tüm kaynakları (JavaScript, CSS, API çağrıları, fontlar vb.) da çekmeye çalışır. Ancak bu kaynakların hepsi tarama ve dizine ekleme açısından gerekli değildir. Gereksiz kaynakların yüklenmesi, hem sunucuya ekstra yük bindirir hem de tarama bütçesini tüketir. Peki, hangi kaynaklar gereksiz sayılabilir?
- Tema veya eklentiye ait kullanılmayan CSS/JS dosyaları
- 3. parti scriptler (ör. kullanılmayan izleme kodları, sosyal medya widget’ları)
- REST API çağrıları (ör. WordPress’te /wp-json/ gibi)
- PDF, test sayfaları veya kullanıcıya özel dosyalar
Googlebot, taramaya değer içeriğe ulaşabilmek için gereksiz yere daha fazla zaman harcar. Bu durum sunucu yanıt süresini artırır ve taranabilecek toplam sayfa sayısını azaltır. Ayrıca bazı durumlarda gereksiz kaynakların yüklenmesi, kritik içeriklerin geç görünmesine neden olur. Sonuç olarak hem tarama bütçesi verimsiz kullanılır hem de önemli sayfaların indekslenmesi gecikebilir.
- Robots.txt kullanımı: Googlebot’un taramasına gerek olmayan CSS, JS ve API yollarını engelleyin.
- Kaynak temizliği: Kullanılmayan eklenti ve scriptleri tamamen kaldırın.
- Asenkron yükleme: Zorunlu 3. parti scriptleri sayfa yüklemesini yavaşlatmayacak şekilde asenkron ekleyin.
- Critical CSS yaklaşımı: Sadece sayfa açılışında gerekli olan CSS kodlarını önden yükleyin.
Örneğin, bir WordPress sitesinde /wp-json/ dizini açık bırakıldığında, Googlebot yüzlerce REST API endpoint’i taramaya çalışabilir. Oysa bu içerikler SEO için hiçbir değer taşımaz. Robots.txt ile engellemek tarama bütçesini korur.
6. 304 Not Modified Kullanımı
Googlebot, daha önce taradığı sayfaları düzenli aralıklarla tekrar ziyaret eder. Eğer sayfa değişmemişse aynı içeriği yeniden indirmek gereksiz bir tarama bütçesi israfıdır. İşte burada HTTP 304 Not Modified yanıtı devreye girer.
304 Not Modified, taranan sayfanın en son ziyaretten bu yana değişmediğini belirtir. Googlebot bu yanıtı aldığında sayfanın içeriğini tekrar indirmez, yalnızca önceden dizine aldığı veriyi kullanmaya devam eder. Böylece hem tarama süresi kısalır hem de sunucuya yük binmez.
Örneğin, bir haber sitesinde, “2023 Seçim Sonuçları” başlıklı haber güncellenmemişse Googlebot sayfayı tekrar indirmek yerine 304 yanıtı alır. Böylece bütçesini yeni haberler için kullanır.
- Sunucu yapılandırmasında If-Modified-Since ve ETag başlıkları doğru şekilde ayarlanmalıdır.
- Sayfa değişmediğinde sunucu 304 yanıtı dönecek şekilde optimize edilmelidir.
- Düzenli testlerle (ör. curl veya log analizi) yanıtların doğru verildiği kontrol edilmelidir.
304 Not Modified, tarama bütçesini korumak için kritik bir yöntemdir. Googlebot’u gereksiz tekrar taramalardan kurtarır ve önemli içeriklere daha fazla zaman ayırmasını sağlar.
7. İçerik Önceliklendirme (Önemli Sayfaların Hızlı Taranmasını Sağlamak)
Tarama bütçesini verimli kullanmanın en etkili yollarından biri de önemli sayfaların Googlebot tarafından daha hızlı keşfedilmesini sağlamaktır. Büyük sitelerde her sayfa eşit önemde değildir; bu yüzden öncelikli içerikler öne çıkarılmalıdır. Peki, hangi sayfalar önceliklendirilmeli?
- En çok trafik getiren ürün ve kategori sayfaları
- Dönüşüm odaklı sayfalar (satış, kayıt, hizmet tanıtımları)
- Haber sitelerinde yeni ve güncel içerikler
- Uluslararası sitelerde hreflang ile işaretlenmiş ana sürümler
Google, sınırlı olan tarama bütçesini her zaman daha yüksek önceliğe sahip sayfalara ayırır. Bu sayede kampanya sayfaları, yeni ürünler veya gündemle ilgili haberler gibi kritik içerikler çok daha hızlı indekslenir. Aynı zamanda tarama bütçesinin doğru kullanılması, sitenin genel mimarisini de daha verimli hale getirir. Böylece hem kullanıcı deneyimi iyileşir hem de arama motorları sitenizi daha etkili bir şekilde tarar. Peki, önceliklendirme nasıl yapılır?
- Ana sayfadan bağlantı: Önemli içeriklerinize doğrudan ana sayfadan link verin.
- İç linkleme: Blog yazıları ve kategori sayfalarından kritik sayfalara link ekleyin.
- Site haritasına ekleme: Sık güncellenen sayfaları site haritasına dahil edin.
- Ping / hızlı bildirim: Yeni sayfalar eklendiğinde Search Console veya API üzerinden Google’a bildirim gönderin.
- Frekans kontrolü: Güncel olmayan, değeri düşük içerikleri öncelik listesinden çıkarın.
Örneğin, bir e-ticaret sitesinde yeni gelen ürünlerin hızlı indekslenmesi gerekiyorsa, bu ürünlere ana sayfadan “Yeni Sezon Ürünleri” bölümüyle link verilebilir. Böylece Googlebot bu ürünleri kısa sürede keşfeder.
8. Mobil Uyumluluk ve Responsive Tasarım
Google, uzun süredir mobile-first indexing yaklaşımını kullanıyor. Yani bir sitenin dizine eklenmesinde ve değerlendirilmesinde öncelikli olarak mobil versiyon dikkate alınıyor. Bu nedenle mobil uyumluluk yalnızca kullanıcı deneyimi için değil, aynı zamanda tarama bütçesinin verimli kullanılması için de kritik bir faktördür.
- Responsive tasarım: Aynı URL’den tüm cihazlara uyumlu içerik sunun.
- Mobil hız optimizasyonu: Görselleri küçültün ve lazy load kullanın.
- Görsel ve medya uyumu: Ekrana sığmayan, taşan veya kayma yapan öğeleri düzenleyin.
- Kritik içerik eşitliği: Mobil ve masaüstü sürümlerde aynı içerik sunulduğundan emin olun.
Örneğin, bir haber sitesi düşünelim. Mobilde ana içerik küçük fontlarla sıkışmış veya reklamlarla kapatılmışsa Googlebot içeriği anlamakta zorlanabilir. Bu da aynı sayfanın tekrar tekrar taranmasına ve tarama bütçesinin boşa gitmesine yol açar.
Tarama Bütçesinin Ölçülmesi ve İzlenmesi
Tarama bütçesini optimize etmek kadar düzenli olarak ölçmek ve izlemek de önemlidir. Çünkü yapılan değişikliklerin etkisini görmek, olası sorunları erken fark etmek ve stratejiyi doğru yönlendirmek ancak sağlıklı takip ile mümkündür. Google Search Console raporları, log dosyası analizleri ve çeşitli SEO araçları sayesinde Googlebot’un sitenizi nasıl taradığını anlayabilir, tarama bütçenizin verimli kullanılıp kullanılmadığını net bir şekilde görebilirsiniz.
Google Search Console Crawl Stats Raporu
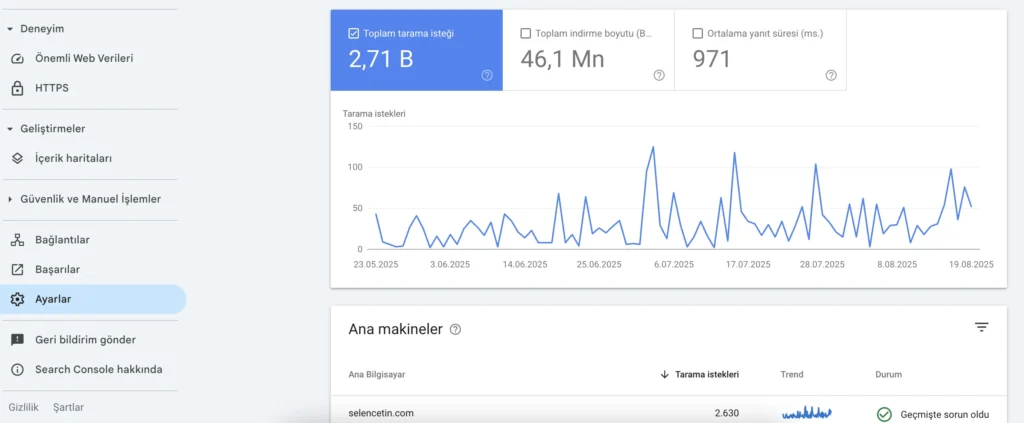
Tarama bütçesini ölçmenin en temel yollarından biri, Google Search Console’daki Crawl Stats (Tarama İstatistikleri) raporudur. Bu rapor, Googlebot’un sitenizde yaptığı taramaların ayrıntılı bir özetini sunar.
- Toplam tarama sayısı: Googlebot’un belirli bir süre içinde kaç istek gönderdiğini gösterir.
- Tarama nedenleri: Hangi sayfaların keşif, güncelleme veya diğer nedenlerle tarandığını görebilirsiniz.
- İstek türleri: HTML, CSS, JS, resim, video gibi hangi içerik türlerinin ne sıklıkla tarandığını raporlar.
- Sunucu yanıt süreleri: Googlebot’un sitenizden ne kadar hızlı yanıt aldığını gösterir.
- Hata oranları: 404, 5xx gibi sorunlu yanıtların yüzdesini görebilirsiniz.
Crawl Stats raporu, Googlebot’un sitenizi nasıl gördüğünü ve hangi alanlarda bütçenin boşa gittiğini anlamanın en güvenilir kaynağıdır. Düzenli takip edilmesi, tarama stratejinizin ne kadar işe yaradığını ölçmek için kritik öneme sahiptir
Sunucu Log Analizi
Tarama bütçesini izlemenin en detaylı yöntemlerinden biri sunucu log analizidir. Sunucu logları, sitenize gelen her isteği kayıt altına alır ve Googlebot’un hangi sayfaları ne sıklıkla taradığını doğrudan görmenizi sağlar.
- Googlebot’un ziyaret ettiği URL’ler: Hangi sayfalar sık taranıyor, hangileri göz ardı ediliyor.
- Tarama frekansı: Önemli sayfalar ne kadar sürede bir ziyaret ediliyor?
- Hatalar: 404, 500 gibi hatalı yanıtların Googlebot’a ne kadar yansıdığı.
- Kaynak israfı: Parametreli URL’ler, filtreleme sayfaları veya düşük değerli içeriklerin tarama oranı.
- Renderlama etkisi: Googlebot’un JS/CSS gibi ek kaynakları ne sıklıkla çağırdığı.
Sunucu log analizi, tarama bütçesini anlamanın en net yoludur. Çünkü doğrudan Googlebot’un gerçek davranışlarını ortaya koyar. Bu sayede stratejilerinizi somut verilere dayandırabilirsiniz.
Üçüncü Parti SEO Araçları (Semrush, Ahrefs, Screaming Frog vb.)
Tarama bütçesini analiz ederken yalnızca Google Search Console ve log dosyalarıyla sınırlı kalmak gerekmez. Üçüncü parti SEO araçları, tarama davranışlarını daha görsel, karşılaştırmalı ve aksiyon alınabilir hale getirir.
- Screaming Frog Log File Analyzer: Log dosyalarını işleyerek Googlebot’un hangi sayfalara odaklandığını netleştirir.
- Ahrefs / Semrush: Site denetim araçlarıyla tarama sorunlarını ortaya çıkarır.
- OnCrawl, Botify, Ryte: Büyük sitelerde detaylı tarama ve log analizi yaparak tarama bütçesi israfını görselleştirir.
- Sitebulb: Özellikle orta ölçekli siteler için tarama frekansı, erişilebilirlik sorunları ve iç link yapısını analiz eder.
Üçüncü parti SEO araçları, tarama bütçesi yönetimini veri odaklı hale getirir. Google’ın nasıl davrandığını anlamak ve sorunlu alanları hızla tespit etmek için bu araçların kullanımı büyük avantaj sağlar.
Sonuç olarak tarama bütçesi, özellikle büyük ve dinamik siteler için SEO başarısında kritik bir unsurdur. Doğrudan bir sıralama faktörü olmasa da Googlebot’un sitenizi ne kadar verimli tarayabildiği, içeriklerinizin arama sonuçlarında ne kadar hızlı ve sağlıklı görüneceğini belirler.
Kaynakça
Google. (t.y.). Crawl budget management for large sites. Google Search Central. https://developers.google.com/search/docs/crawling-indexing/large-site-managing-crawl-budget
Yoast. (t.y.). How to optimize your crawl budget. Yoast. https://yoast.com/crawl-budget-optimization/
Rank Math. (t.y.). What is crawl budget?. Rank Math. https://rankmath.com/seo-glossary/crawl-budget/
Semrush. (t.y.). Crawl budget: What is it and why is it important for SEO?. Semrush. https://www.semrush.com/blog/crawl-budget/
Ahrefs. (t.y.). What is crawl budget and why does it matter for SEO?. Ahrefs. https://ahrefs.com/seo/glossary/crawl-budget
Search Engine Journal. (2023). 9 tips to optimize crawl budget for SEO. SEJ. https://www.searchenginejournal.com/technical-seo/crawl-budget/